"a car on the road"
⇨ "a gold car on the road"
⇨ "a snowy car on the road"
⇨ "a porsche on the road"
"a small castle on the table"
⇨ "a snowy castle on the table"
⇨ "a jelly castle on the table"
⇨ "a croissant"
"a round hat"
⇨ "a camo round hat"
⇨ "a gold round hat"
⇨ "a silver round hat"
"flowers"
⇨ "lego blossom"
⇨ "cherry blossom"
⇨ "popcorn flower"
Abstract
In this work, we introduce an efficient text-guided editing NeRF with zero-shot setting using diffusion model and latent space NeRF. Recently, there has been a significant advancement in text-to-image diffusion models, leading to groundbreaking performance in 2D image generation. These advancements have been extended to 3D models, enabling the generation of novel 3D objects from textual descriptions. This has evolved into NeRF editing methods, which allow the manipulation of existing 3D objects through textual conditioning. However, existing NeRF editing techniques have faced limitations in their performance due to slow training speeds and the use of loss functions that do not adequately consider editing. To address this, here we present a novel 3D NeRF editing approach dubbed ED-NeRF by successfully embedding real-world scenes into the latent space of the latent diffusion model (LDM) through a unique refinement layer. This approach enables us to obtain a NeRF backbone that is not only faster but also more amenable to editing compared to traditional image space NeRF editing. Furthermore, we propose an improved loss function tailored for editing by migrating the delta denoising score (DDS) distillation loss, originally used in 2D image editing to the three-dimensional domain. This novel loss function surpasses the well-known score distillation sampling (SDS) loss in terms of suitability for editing purposes. Our experimental results demonstrate that ED-NeRF achieves faster editing speed while producing improved output quality compared to state-of-the-art 3D editing models.
Method
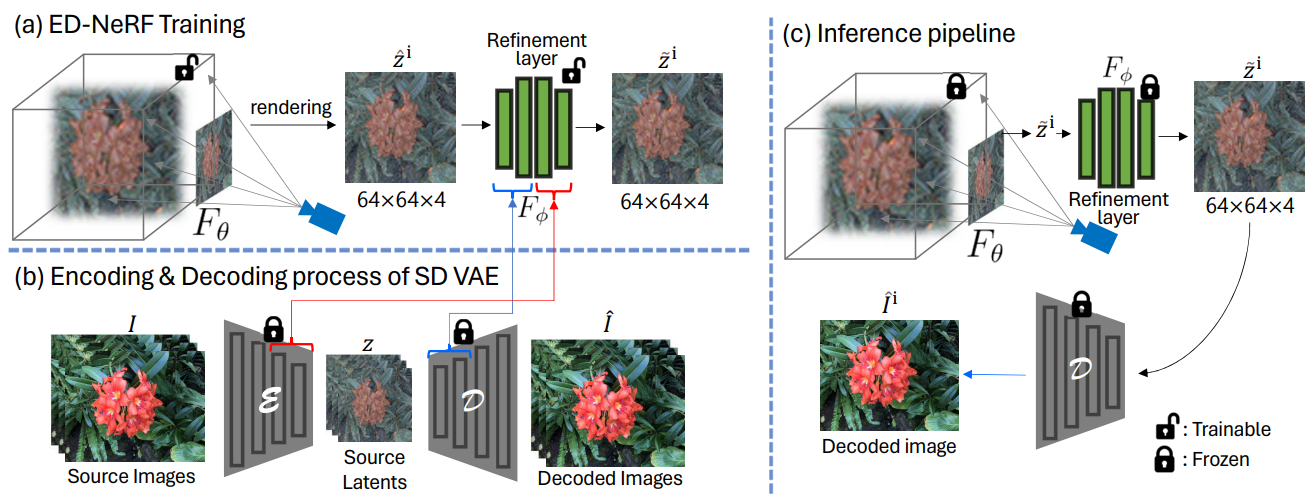
Overall pipeline of training and inference stage. (a) We optimize ED-NeRF in the latent space, supervised by source latent. Naively matching NeRF to a latent feature map during optimization can degrade view synthesis quality. (b) Inspired by the embedding process of Stable Diffusion, we integrated additional ResNet blocks and self-attention layers as a refinement layer. (c) All 3D scenes are decoded from the Decoder when ED-NeRF renders a novel view feature map.
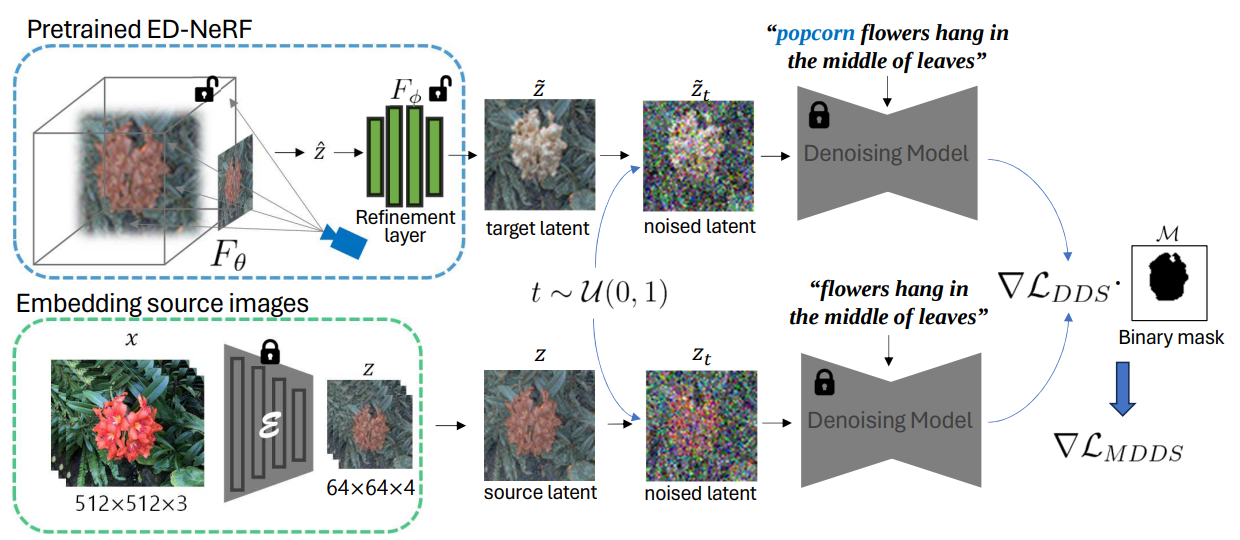
Expanding DDS into 3D for ED-NeRF editing. Pretrained ED-NeRF renders the target latent feature map, and a scheduler of the denoising model perturbs it to the sampled time step. Concurrently, the scheduler adds noise to the source latent using the same time step. Each of them is fed into the denoising model, and the DDS is determined by subtracting two different SDS scores. In combination with a binary mask, masked DDS guides NeRF in the intended direction of the target prompt without causing unintended deformations.
Comparison with state-of-the-art approaches
|
Original NeRF
|
Instruct NeRF2NeRF
|
CLIP-NeRF
|
|---|---|---|
|
NeRF-ART
|
Mask + sds
|
ED-NeRF (ours)
|
"a car" ⇨ "a gold car"
|
Original NeRF
|
Instruct NeRF2NeRF
|
CLIP-NeRF
|
|---|---|---|
|
NeRF-ART
|
Mask + sds
|
ED-NeRF (ours)
|
"a small castle" ⇨ "a jelly castle on the table"
|
Original NeRF
|
Instruct NeRF2NeRF
|
CLIP-NeRF
|
|---|---|---|
|
NeRF-ART
|
Mask + sds
|
ED-NeRF (ours)
|
"flowers" ⇨ "popcorn flowers"
|
Original NeRF
|
Instruct NeRF2NeRF
|
CLIP-NeRF
|
|---|---|---|
|
NeRF-ART
|
Mask + sds
|
ED-NeRF (ours)
|